Perceptual models
 Perceptual models are a vital part of our work. They help us to quantify "what happens in our brain" and can be used to make predictions on how loud an
annoying noise is or how to set loudness correctly in a hearing aid.
We are a main contributor to ISO 532-3, the Moore-Glasberg-Schlittenlacher model for time-varying loudness.
Perceptual models are a vital part of our work. They help us to quantify "what happens in our brain" and can be used to make predictions on how loud an
annoying noise is or how to set loudness correctly in a hearing aid.
We are a main contributor to ISO 532-3, the Moore-Glasberg-Schlittenlacher model for time-varying loudness.
The model behind ISO 532-3 is not only an international standard and recognised to contribute to the UN Goal of good health and well-being. It is widely used in industry,
for example to design quiet aircraft, to optimize the sound quality in technical products or to control
the volume in broadcasting devices. We hope that it will become law to set perceptually more valid limits for noise pollution.
ISO/AWI 532-3
Moore, B.C.J., Jervis, M., Harries, L., Schlittenlacher, J. (2018)
Moore, B. C. J., Glasberg, B. R., Varathanathan, A., Schlittenlacher, J. (2016)
Bayesian Active Learning
Bayesian Active Learning has the potential to transform clinical testing. It is both faster and more accurate than traditional methods because it
always asks the most informative question. Thanks to maintaining and constantly updating a probabilistic model of the outcome, it automatically detects errors, too.
Look at the two false positives at 200 and 250 Hz (blue circles in lower left): After gathering further data, the algorithm puts more trials in that
region and detects the true threshold.
We developed tests for several audiological applications: Audiogram, auditory filters, dead regions, equal-loudness contours. For some of them
testing time was reduced from several hours to a duration that is suitable for clinical practice. Since the tests run fully automatic, the audiologist
can focus on more important tasks while the test is run, or interpret the data in real time.
Schlittenlacher, J., Turner, R. E., Moore, B. C. J. (2018). Audiogram
Schlittenlacher, J., Turner, R. E., Moore, B. C. J. (2018). Dead regions
Schlittenlacher, J., Turner, R. E., Moore, B. C. J. (2020). Auditory filters
Schlittenlacher, J., Moore, B. C. J. (2020). Equal-loudness contours
Text-to-speech for speech and hearing sciences
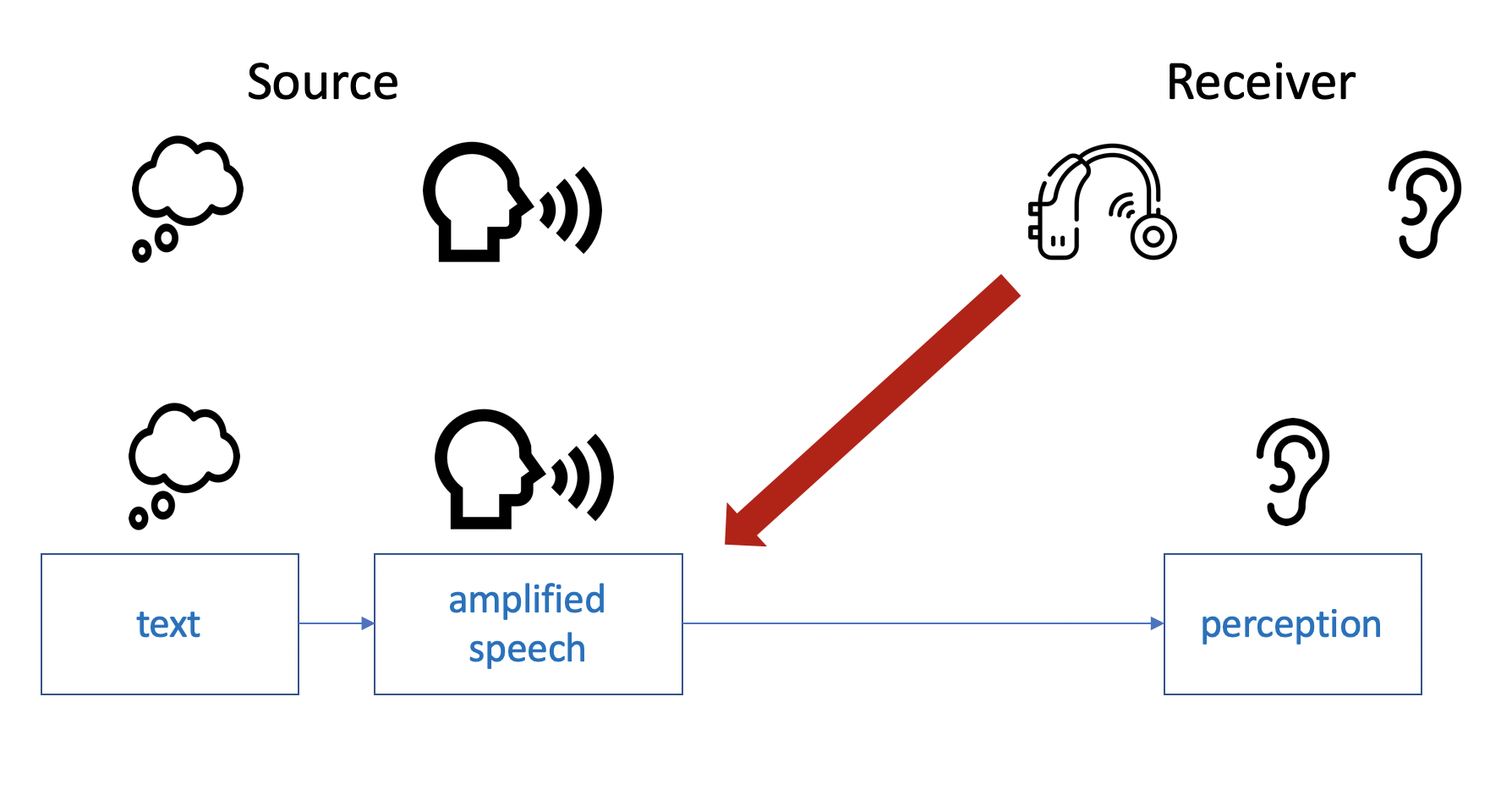 Neural vocoders are huge deep neural networks that can generate speech from text. They are more or less the equivalent for sound what ChatGPT is for text.
We use them to study basic questions of speech perception and to investigate and overcome barriers for the hearing impaired.
Neural vocoders are huge deep neural networks that can generate speech from text. They are more or less the equivalent for sound what ChatGPT is for text.
We use them to study basic questions of speech perception and to investigate and overcome barriers for the hearing impaired.
Automatic Speech Recognition
How can we improve speech perception in cochlear implants? When we have a fully computational mode. that predicts speech perception with cochlear implants, we can let the computer try thousands of settings and choose the best.
Presented as part of my talk at VCCA 2021 on 25 June, computationalaudiology.com
Brochier, T., Schlittenlacher, J., ..., Bance, M. (2022). Speech model for cochlear implants
Code at github.com/js2251/ASRbasic
Knowledge distillation
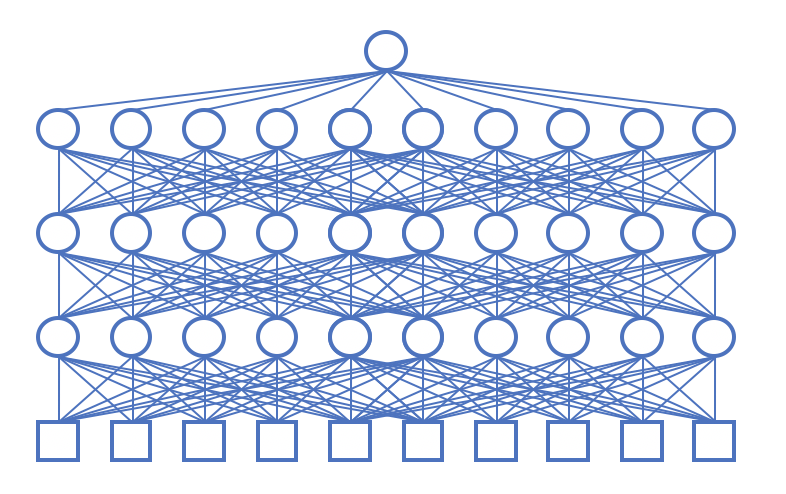 Our loudness model had one disadvantage: Being a complex model that mimics human physiology and neural processing accurately, computations took
some time. We trained a neural network to produce the same outputs as the loudness models, and it did so at high accuracy - differences were
smaller than what a human would notice. We reduced the computation time for a 24-hours long recording from 50 days to a few minutes on a
graphic processor unit.
Our loudness model had one disadvantage: Being a complex model that mimics human physiology and neural processing accurately, computations took
some time. We trained a neural network to produce the same outputs as the loudness models, and it did so at high accuracy - differences were
smaller than what a human would notice. We reduced the computation time for a 24-hours long recording from 50 days to a few minutes on a
graphic processor unit.
This strategy is known as knowledge distillation. Deep neural networks can be run faster because hardware is optimized for them. Our colleagues
followed us and used the same approach for further perceptual models, for example speech quality. We are looking
forward to small and energy-efficient AI hardware that will allow us to run all of them in a hearing aid.
Schlittenlacher, J., Moore, B. C. J. (2020)
Schlittenlacher, J., Turner, R.E., Moore, B.C.J. (2019)
Irrelevant Speech Effect
 What are the features of speech? What makes a sound speechlike?
What are the features of speech? What makes a sound speechlike?
It has been found that speech disturbs our short-term memory more than any other sound. While we learn about as efficiently in continuous noise as we
do in silence, our performance drops significantly when there is speech in the background.
We use this effect to investigate which features make a sound speechlike by systematically manipulating and degrading speech in listening experiments.
It is mainly the changes over time between different frequency bands that cause the Irrelevant Speech Effect - a feature that is not well extracted in most of the common feature representations.
Schlittenlacher, J., Staab, K., Çelebi, Ö., Samel, A., Ellermeier, W. (2019)
Reaction time
 What can we learn about the neural pathways that start at the ear by comparing loudness to simple reaction time? A lot!
What can we learn about the neural pathways that start at the ear by comparing loudness to simple reaction time? A lot!
A reaction to the start of a sound to pressing a button typically takes 150 to 300 ms. It is about 5 ms faster when listening with both ears compared to one ear. The louder the sound, the faster the reaction - but with some constraints.
Schlittenlacher, J., Ellermeier, W., Avci, G. (2016)
Schlittenlacher, J., Ellermeier, W. (2015)
Schlittenlacher, J., Ellermeier, W., Arseneau, J. (2014)
Software development
Some of our code is on GitHub:
If there is no license indicated, please contact us. We are usually always happy for it being used in academic and non-commercial research.
Consulting
The most exciting part of consulting is bringing state-of-the-art research right into production - and subsequently driving research with new ideas.
We consult various projects and companies. See for example our presentations at the Uber Elevate summits in 2017 and 2018, the seminal conferences for "flying taxis" and urban air mobility: